SPLUNK – неведома зверушка и где она обитает

При централизованном управлении распределенных систем возникает вопрос в мониторинге этих систем, причем желательно в режиме реального времени, с возможностью оперативного вмешательства в случае наступления инцидента.
Эффективно решить такую задачу позволяет централизация сбора, хранения и обработки журналов наблюдаемых систем. Также, централизованное хранение логов позволяет восстановить ход событий даже в случае полного уничтожения целевой системы, включая журналы событий.
Сегодня расскажем о подключении OS на базе Linux систем простыми (надеюсь) словами.
За основу комплекса взят Splunk-сервер актуальной версии 9.0.5, который уже успешно принимает данные от Windows и других систем. При установке сервера назначен отдельный порт 39801, на котором сервис-listener и будет принимать у нас все данные от агентов.
Перед началом подключения следует определиться: каким именно способом собирать данные с серверов, и как Вы потом будете их обрабатывать. Постройте себе цепочку от события, которое может гипотетически произойти на сервере, которое Вы хотите отследить, и до реакции на это событие.
Возьмем в качестве примера несложный инцидент: повышение (или попытка повышения) прав пользователя с «обычного» до уровня root в OS LINUX. Цепочка будет такой:
- Пользователь успешно (или неуспешно) повысил себе права до root введя команду sudo -i.
- Событие зафиксировалось в логах сервера (клиента - по отношению к серверу Splunk)
- Событие передается с клиента на сервер Splunk
- На сервере Splunk событие попадает в определенный индекс, где будет обрабатываться и главное – храниться для ретроспективного анализа.
Дополнительно, для некоторых событий, их можно нормализировать еще на стороне клиента, но лучше, чтобы они попадали на сервер в чистом, незамутнённом виде. Особенно критические.
Итак, событие произошло, и оно должно быть отражено в логах клиента. Два основных метода – сбор «родных» логов LINUX и сбор демоном auditd. Оба способа имеют свои отличия в настройке и обработке.
- Штатно, логи собираются в папке /var/log/. Возможно, этого будет вполне достаточно, но это зависит от того, какие у Вас сервисы и каталоги должны мониториться. Будем стараться мониторить всю папку и посмотрим, какие данные попадут в индекс автоматически.
- Можно установить auditd – этот демон будет собирать все события в один файл. Auditd имеет свой собственный файл конфигурации, и можно указывать что и каким образом он будет собирать. Минусом auditd можно считать излишнюю нагрузку на систему, но это регулируется или его тонкими настройками, или увеличением объема памяти. По умолчанию файл создается по адресу /var/log/audit/audit.log
Учтите этот момент, если будете настраивать одновременно мониторинг папки /var/log/ и журнала демона auditd, чтобы у Вас не дублировались записи событий.
Определившись с тем, что и как мы будем собирать, можно переходить к этапу передачи этой информации на сервер. Для этого будем использовать универсальный сервис от Splunk – Splunk Forwarder. Для различных систем его можно загрузить по ссылке : https://www.splunk.com/en_us/download/universal-forwarder.html#tabs/linux (требуется регистрация).
Задача форвардера – передать информацию из точки А в точку Б, где точкой А выступает лог-файл, а точной Б – сервер Splunk. Кроме этого, форвардер может передавать данные «по цепочке»: например, с нескольких серверов в одном сегменте сети, которые не имеют прямого доступа к серверу Splunk, клиентские форвардеры передают данные на консолидирующий форвардер, а он в свою очередь передает на сервер по отдельному, специально для него выделенному каналу, в другую подсеть.
Установка форвардера на наблюдаемый сервер начинается с создания индивидуального пользователя и группы, под которым форвардер и будет запускаться. По умолчанию это пользователь splunk и группа splunk.
Создайте пользователя и группу:
#useradd -m splunk
#groupadd splunk
Создайте домашнюю директорию для форвардера:
#export SPLUNK_HOME="/opt/splunkforwarder"
#mkdir $SPLUNK_HOME
Скачaнный дистрибутив в архиве .tgz распакуйте в папку /opt/splunkforwarder/ и назначьте владельцем нового пользователя:
#chown -R splunk:splunk $SPLUNK_HOME
Переключитесь на нового пользователя splunk или любого другого непривилегированного пользователя и зайдите в папку /opt/splunkforwarder/bin/ и найдите скрипт splunk.
Выполните первый запуск скрипта, при котором он проинсталлирует необходимые компоненты
$sudo $SPLUNK_HOME/bin/splunk start --accept-license
В дальнейшем этот скрипт понадобится для перезапуска форвардера, остальные настройки указываются только в конфигурационных файлах.
./splunk stop – остановка сервиса
./splunk start – запуск сервиса
./splunk status – проверка текущего статуса
После инсталляции в папке /opt/splunkforwarder/etc/system/ появятся три интересующие нас папки с настройками
/default – в этой папке находятся все конфигурационные файлы, которые действуют по умолчанию. Изменять их нельзя.
/README – подробное описание каждого параметра в каждом файле.
/local – интересующая нас папка. Все конфигурационные файлы, помещенные в эту папку, имеют приоритет над дефолтными настройками.
Для простой передачи данных с клиента на сервер Splunk нам потребуется два файла, определяющие «что» собирать, и «куда» отправлять.
outputs.conf – указывает адрес целевого сервера или узлового форвардера.
Для одного сервера достаточно следующей конфигурации:
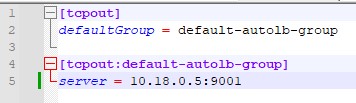
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
server = 10.10.10.5: 39801
Несмотря на то, что сервер и клиент один, предварительно нужно указать группу по умолчанию, в которую будет входить клиент. Когда клиентов будет несколько, нужно указывать ту же самую группу.
Обязательно проверьте, виден ли указанный вами порт с клиентской машины (например, с помощью команды: $ telnet 10.10.10.5 39801).
Inputs.conf – перечисляет что именно собирать и в какой индекс отправлять.
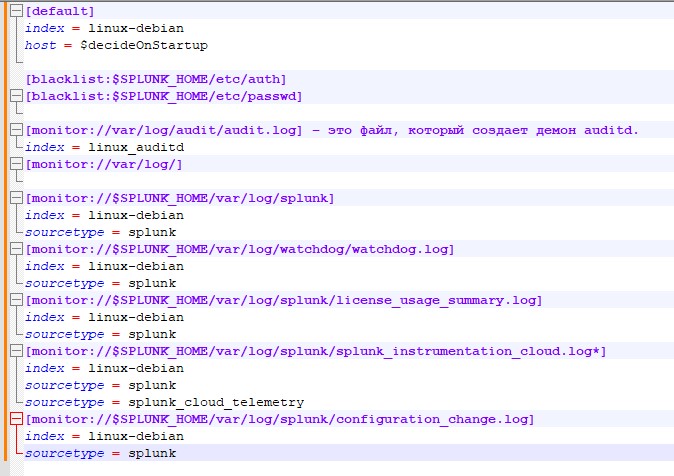
В начале укажем конфигурацию, которая будет считаться по умолчанию
[default]
index = linux-debian – индекс, куда будут попадать данные, если не указанно другое.
host = $decideOnStartup – имя данного сервера, как он в последствии будет отображаться в логах спланка. Важный момент – если оставить значение $decideOnStartup, то будет взято имя сервера, которое он получил при инсталляции. Но в случае виртуализированных серверов, и если они создавались клонированием, то Вы получите одинаковые имена хостов, которые смешаются в индексе. Так же не следует привязываться к IP адресу машины – многие события не имеют привязки к адресу и никак его не отображают. Гораздо надежнее будет вручную указать имя сервера, как Вы хотите видеть его логах спланка.
Укажем черный список файлов, их расположение, которые не надо мониторить
[blacklist:$SPLUNK_HOME/etc/auth]
[blacklist:$SPLUNK_HOME/etc/passwd]
Указываем, что нужно мониторить и куда складывать, в какой индекс:
[monitor://var/log/audit/audit.log] – это файл, который создает демон auditd.
index = linux_auditd – обратите внимание, для него создан отдельный индекс на сервере. Если этот параметр не указать, то будет выбран индекс linux-debian, указанный в блоке [default] в начале файла.
[monitor://var/log/] – данный пункт указывает что мониторить нужно всю папку /var/log/. Поскольку не указан дополнительный параметр index, данные попадут по умолчанию в index = linux-debian
Обращаем внимание - в такой конфигурации будет повторно мониториться файл /var/log/audit/audit.log, и информация из него будет «попадать» в два индекса: и linux-debian, и linux_auditd
Не забываем про мониторинг самого форвардера, ведь в случае его отключения мы перестанем получать логи системы:
[monitor://$SPLUNK_HOME/var/log/splunk]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/watchdog/watchdog.log]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/splunk/license_usage_summary.log]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/splunk/splunk_instrumentation_cloud.log*]
index = linux-debian
sourcetype = splunk
sourcetype = splunk_cloud_telemetry
[monitor://$SPLUNK_HOME/var/log/splunk/configuration_change.log]
index = linux-debian
sourcetype = splunk
В данном случае, при добавлении переменной sourcetype = splunk информация о работе форвардера будет попадать в общий индекс, но тип данных будет указан как splunk. Это будет полезно для последующего анализа данных и построении запросов.
Рекомендуется мониторить следующие директории и источники:
/etc
/var/log
/home/*/.bash_history
/root/.bash_history
/var/adm
/Library/Logs
После внесения изменений в любые файлы конфигурации необходимо перезапустить форвардер, что бы они вступили в силу
./splunk stop – остановка сервиса
./splunk start – запуск сервиса
В процессе настройки рекомендуется включить на сервере запрос index="linux-debian" или index="linux_auditd" а период времени поставить REAL-TIME - 5 minute window. Вы сразу же увидите данные, поступившие в индекс после перезапуска форвардера – или их изменение, или что они вообще начали поступать на сервер.
Если все было проделано правильно, то после окончательного старта сервиса forwareder в самом сервере Splunk увидим «ожившие» новые индексы:

И теперь можно привлекать весь потенциал продукта Splunk для построения системы мониторинга событий и выявления инцидентов.
Например, с чего, собственно, начиналась статья – событие получения пользователем root прав. Для этого пишем простой запрос, с учетом того индекса, куда мы заливаем данные.
index="linux_auditd" acct=root audit_description="User session start"| table UID host
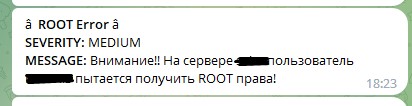
Данный запрос вернет все события начала сессии с правами root и выведет в табличку имя пользователя и имя хоста, на котором это случилось. Данный запрос сохраняем как алерт, назовем, к примеру «ROOT на серверах» Укажем тип алерта “Real-time” и длительность в 365 дней (да, тут надо помнить, что через год он отключиться). Добавим действие, которое нужно выполнить при возникновении события – будем отправлять сообщения в телеграмм. В поле сообщения введем «Внимание!! На сервере $result.host$ пользователь $result.UID$ получил ROOT права!» - это сформирует нам нужное сообщение из получаемых полей.
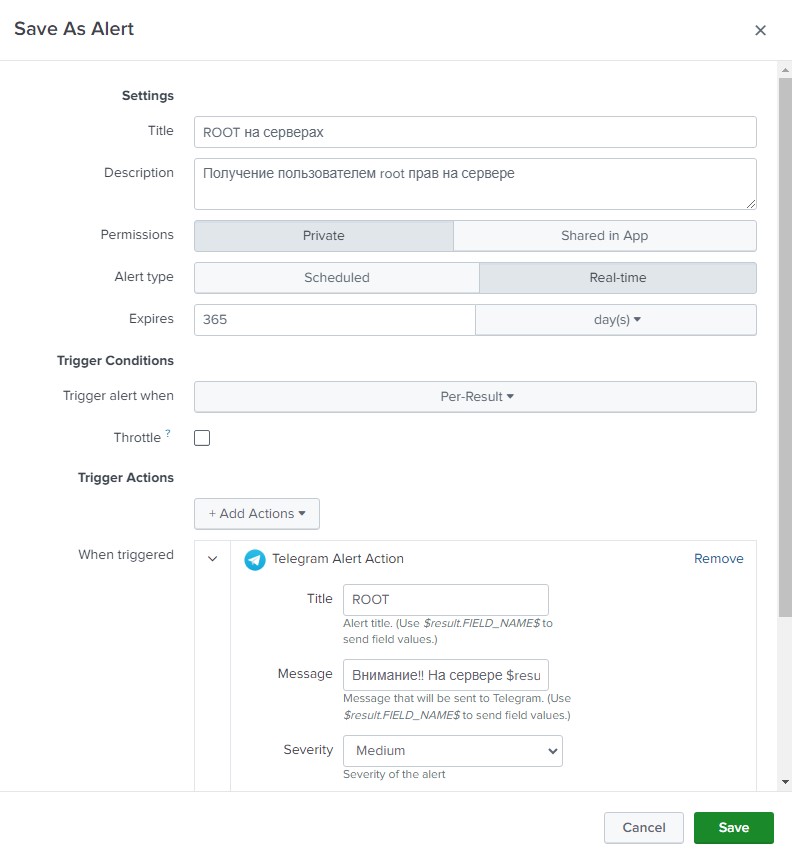
Если все правильно, то в телеграмм должны приходить сообщения с задержкой примерно 5-8 секунд.
По аналогии, можно сделать другой алерт, который будет срабатывать не тогда, когда пользователь успешно получит права, а когда он не смог их получить, хотя и пытался. Для этого сделаем такой запрос:
index="linux_auditd" action=failure type=USER_AUTH | table UID host addr
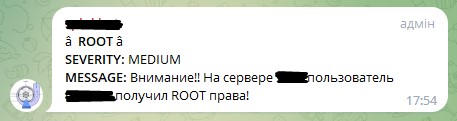
Этот запрос выдаст нам ошибки при авторизации пользователя. Сделаем из него алерт, но с тем отличием от предыдущего, что срабатывать он будет не по однократному событию (может просто админ не с первого раза по клавиатуре попал), а при возникновении 10 таких событий в период 5 минут. Так же учтем, что после срабатывания алерта он должен временно отключиться на 6 минут, чтобы не пересчитывать значения за последние 5 минут, которые уже посчитал.
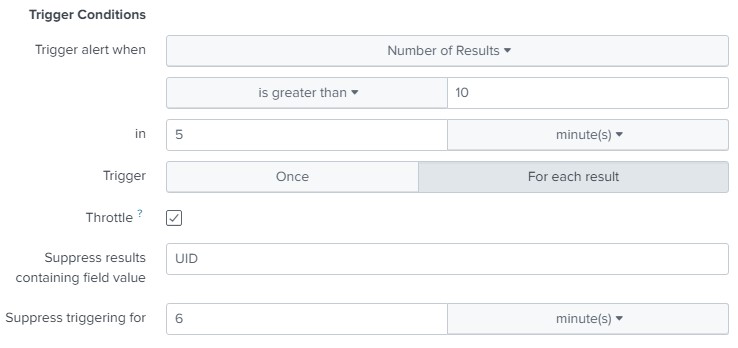
В таком случае Вы получите такое сообщение в телеграме:
В данном примере мы учитываем количество повторений в течении 5 минут значения поля UID, но можно настроить алерт просто на количество ошибок, если предположить, что подбор пароля осуществляется не для одной учетной записи, а для различных учеток, хотя чаще всего подбирают пароль к пользователю root или другому, заранее известному, пользователю.
Так же можно настраивать и другие реакции. Например, при 1000 ошибках в течении 5 минут выполнить скрипт, который добавит или включит на фаерфоле правило, изолирующее атакующий хост. IP этого хоста нам вернет переменная addr из нашего запроса.
Таким образом, уважаемые читатели, мы с Вами разобрались, что програмное решение Splunk - это весьма мощный инструмент для централизованного сбора, хранения и обработки журналов OS LINUX.
Изучили, как производится инсталляция, конфигурирование и управление Splunk’om.
На примере LINUX-daemon’a auditd научились поставлять события в индекс Splunk, и пронаблюдали, как производится настройка и отправка оповещений Splunk’a во внешний канал (Telegram).
Продолжение – следует!


