SPLUNK – невідоме звірятко і де воно мешкає

При централізованому управлінні розподілених систем виникає питання моніторингу цих систем, причому бажано як реального часу, з можливістю оперативного втручання у разі настання інциденту.
Ефективно вирішити таке завдання дозволяє централізація збору, зберігання та обробки журналів систем, що спостерігаються. Також централізоване зберігання ліг дозволяє відновити хід подій навіть у разі повного знищення цільової системи, включаючи журнали подій.
Сьогодні розповімо про підключення OS на базі Linux систем простими (сподіваюся) словами.
За основу комплексу взято Splunk-сервер актуальної версії 9.0.5, який успішно приймає дані від Windows та інших систем. При встановленні сервера призначено окремий порт 39801, на якому сервіс-listener і прийматиме у нас усі дані від агентів.
Перед початком підключення слід визначитися: яким саме способом збирати дані з серверів, і як Ви потім їх оброблятимете. Побудуйте собі ланцюжок від події, яка може гіпотетично відбутися на сервері, який Ви хочете відстежити, і до реакції на цю подію.
Візьмемо як приклад нескладний інцидент: підвищення (або спроба підвищення) прав користувача від «звичайного» рівня root в OS LINUX. Ланцюжок буде такий:
- Користувач успішно (або неуспішно) підвищив собі права до root ввівши команду sudo-i.
- Подія зафіксувалося в логах сервера (клієнта - по відношенню до сервера Splunk)
- Подія передається з клієнта на сервер Splunk
- На сервері Splunk подія потрапляє до певного індексу, де оброблятиметься і головне – зберігатиметься для ретроспективного аналізу.
Додатково, для деяких подій їх можна нормалізувати ще на стороні клієнта, але краще, щоб вони потрапляли на сервер у чистому, незамутненому вигляді. Особливо критичні.
Отже, подія відбулася, і вона має бути відображена у логах клієнта. Два основні методи - збір «рідних» ліг LINUX і збір демоном auditd. Обидва способи мають свої відмінності у налаштуванні та обробці.
- Штатно, логи збираються у папці /var/log/. Можливо, цього буде цілком достатньо, але це залежить від того, які у Вас послуги та каталоги повинні моніторитися. Намагатимемося моніторити всю папку і подивимося, які дані потраплять в індекс автоматично.
- Можна встановити auditd – цей демон збиратиме всі події в один файл. Auditd має свій власний конфігураційний файл, і можна вказувати що і яким чином він буде збирати. Мінусом auditd можна вважати зайве навантаження на систему, але це регулюється або його тонкими налаштуваннями або збільшенням обсягу пам'яті. За промовчанням файл створюється за адресою /var/log/audit/audit.log
Врахуйте цей момент, якщо налаштовуватимете одночасно моніторинг папки /var/log/ та журналу демона auditd, щоб у Вас не дублювалися записи подій.
Визначившись з тим, що і як ми збиратимемо, можна переходити до етапу передачі цієї інформації на сервер. Для цього використовуватимемо універсальний сервіс від Splunk – Splunk Forwarder. Для різних систем його можна завантажити за посиланням: https://www.splunk.com/en_us/download/universal-forwarder.html#tabs/linux (потрібна реєстрація).
Завдання форвардера – передати інформацію з точки А до точки Б, де точкою А виступає лог-файл, а точною Б – сервер Splunk. Крім цього, форвардер може передавати дані по ланцюжку: наприклад, з декількох серверів в одному сегменті мережі, які не мають прямого доступу до сервера Splunk, клієнтські форвардери передають дані на консолідуючий форвардер, а він у свою чергу передає на сервер окремо, спеціально для нього виділеного каналу, в іншу підмережу.
Встановлення форвардера на сервер, що спостерігається, починається зі створення індивідуального користувача і групи, під яким форвардер і буде запускатися. За замовчуванням це користувач splunk та група splunk.
Створіть користувача та групу:
#useradd -m splunk
#groupadd splunk
Створіть домашню директорію для форвардера:
#export SPLUNK_HOME="/opt/splunkforwarder"
#mkdir $SPLUNK_HOME
Завантажений дистрибутив в архіві .tgz розпакуйте в папку /opt/splunkforwarder/ і призначте власником нового користувача:
#chown -R splunk:splunk $SPLUNK_HOME
Перейдіть на нового користувача splunk або будь-якого іншого непривілейованого користувача і зайдіть в папку /opt/splunkforwarder/bin/ і знайдіть скрипт splunk.
Виконайте перший запуск скрипта, при якому він установить необхідні компоненти
$sudo $SPLUNK_HOME/bin/splunk start --accept-license
Надалі цей скрипт знадобиться для перезапуску форвардера, інші налаштування вказуються лише у файлах конфігурації.
./splunk stop – зупинка сервісу
./splunk start – запуск сервісу
./splunk status – перевірка поточного статусу
Після інсталяції в папці /opt/splunkforwarder/etc/system/ з'являться три цікаві для нас папки з налаштуваннями
/default – у цій папці є всі конфігураційні файли, які діють за замовчуванням. Змінювати їх не можна.
/README – докладний опис кожного параметра в кожному файлі.
/local - цікава для нас папка. Усі конфігураційні файли, розміщені в цій папці, мають пріоритет над дефолтними налаштуваннями.
Для простої передачі даних з клієнта на сервер Splunk нам знадобиться два файли, що визначають "що" збирати, і "куди" відправляти.
outputs.conf – вказує адресу цільового сервера чи вузлового форвардера.
Для одного сервера достатньо наступної конфігурації:
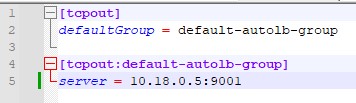
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
server = 10.10.10.5: 39801
Незважаючи на те, що сервер і клієнт один, потрібно вказати групу за замовчуванням, в яку буде входити клієнт. Коли клієнтів буде кілька, потрібно вказувати ту саму групу.
Обов'язково перевірте, чи вказаний вами порт з клієнтської машини (наприклад, за допомогою команди: $ telnet 10.10.10.5 39801).
Inputs.conf – перераховує що саме збирати і до якого індексу відправляти.
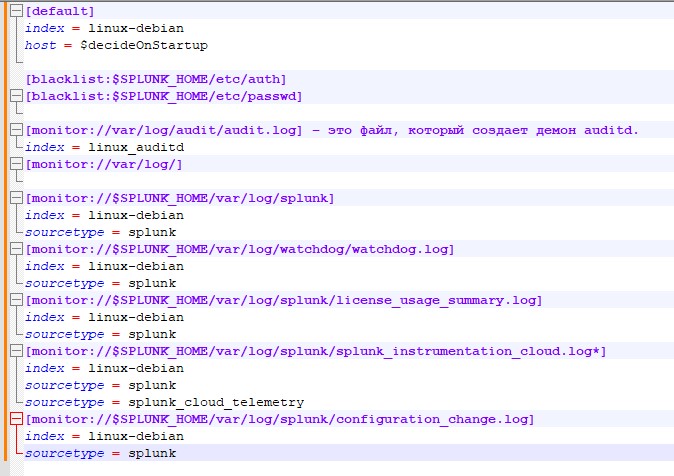
На початку вкажемо конфігурацію, яка вважатиметься за умовчанням
[default]
index = linux-debian – індекс, куди потраплятимуть дані, якщо не зазначено інше.
host = $decideOnStartup - ім'я даного сервера, як він буде відображатися в логах спланка. Важливий момент – якщо залишити значення $decideOnStartup, буде взято ім'я сервера, яке він отримав при інсталяції. Але у випадку віртуалізованих серверів, і якщо вони створювалися клонуванням, Ви отримаєте однакові імена хостів, які змішаються в індексі. Також не слід прив'язуватися до IP-адреси машини - багато подій не мають прив'язки до адреси і ніяк її не відображають. Набагато надійніше буде вручну вказати ім'я сервера, як Ви хочете бачити його логах спланування.
Вкажемо чорний список файлів, їх розташування, які не потрібно моніторити
[blacklist:$SPLUNK_HOME/etc/auth]
[blacklist:$SPLUNK_HOME/etc/passwd]
Вказуємо, що потрібно моніторити і куди складати, в який індекс:
[monitor://var/log/audit/audit .log] – це файл, який створює демон auditd.
index = linux_auditd – зверніть увагу, для нього створено окремий індекс на сервері. Якщо цей параметр не вказати, буде вибрано індекс linux-debian, вказаний у блоці [default] на початку файлу.
[monitor://var/log /] - цей пункт показує, що моніторити необхідно всю папку /var/log/. Оскільки не вказано додатковий параметр index, дані потраплять за замовчуванням до index = linux-debian
Звертаємо увагу - у такій конфігурації буде повторно моніторитися файл /var/log/audit/audit.log, і інформація з нього "попадатиме" у два індекси: і linux-debian, і linux_auditd
Не забуваємо про моніторинг самого форвардера, адже у разі його відключення ми перестанемо отримувати логі системи:
[monitor://$SPLUNK_HOME/var/log/splunk]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/watchdog/watchdog .log]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/splunk/license_usage_summary .log]
index = linux-debian
sourcetype = splunk
[monitor://$SPLUNK_HOME/var/log/splunk/splunk_instrumentation_cloud .log*]
index = linux-debian
sourcetype = splunk
sourcetype = splunk_cloud_telemetry
[monitor://$SPLUNK_HOME/var/log/splunk/configuration_change .log]
index = linux-debian
sourcetype = splunk
В даному випадку, при додаванні змінної sourcetype = splunk інформація про роботу форвардера буде потрапляти до загального індексу, але тип даних буде вказаний як splunk. Це буде корисно для подальшого аналізу даних та побудові запитів.
Рекомендується моніторити такі директорії та джерела:
/etc
/var/log
/home/*/.bash_history
/root/.bash_history
/var/adm
/Library/Logs
Після внесення змін у будь-які файли конфігурації необхідно перезапустити форвардер, щоб вони набули чинності
./splunk stop – зупинка сервісу
./splunk start – запуск сервісу
У процесі налаштування рекомендується включити на сервер запит index="linux-debian" або index="linux_auditd" а період часу поставити REAL-TIME - 5 minute window. Ви відразу ж побачите дані, що надійшли до індексу після перезапуску форвардера – або їх зміна, або що вони взагалі почали надходити на сервер.
Якщо все було зроблено правильно, то після остаточного старту сервісу forwareder у самому сервері Splunk побачимо нові індекси, що «ожили»:

І тепер можна залучати весь потенціал продукту Splunk для побудови системи моніторингу подій та виявлення інцидентів.
Наприклад, із чого, власне, починалася стаття – подія отримання користувачем root прав. Для цього пишемо простий запит з урахуванням того індексу, куди ми заливаємо дані.
index="linux_auditd" acct=root audit_description="User session start"| table UID host
Цей запит поверне всі події початку сесії з правами root та виведе в табличку ім'я користувача та ім'я хоста, на якому це сталося. Цей запит зберігаємо як алерт, назвемо, наприклад «ROOT на серверах» Вкажемо тип алерту “Real-time” і тривалість 365 днів (так, тут пам'ятаймо, що за рік він відключитися). Додамо дію, яку потрібно виконати у разі виникнення події – відправлятимемо повідомлення в телеграм. У полі повідомлення введемо «Увага! На сервері $result.host$ користувач $result.UID$ отримав ROOT права! - це сформує нам необхідне повідомлення з полів.
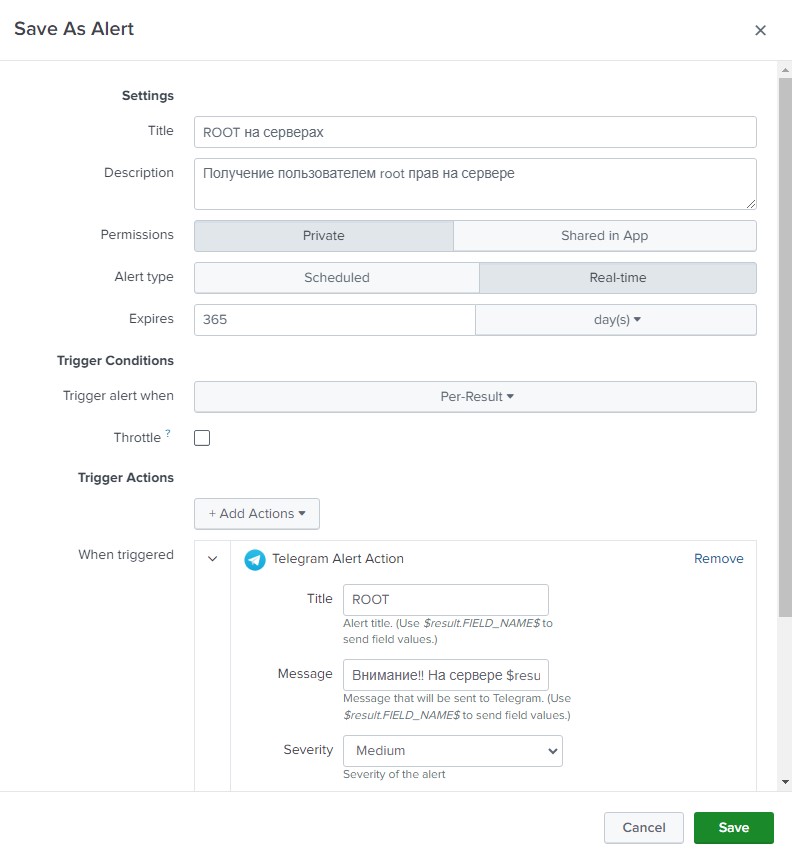
Якщо все правильно, то в телеграм повинні надходити повідомлення із затримкою приблизно 5-8 секунд.
За аналогією, можна зробити інший алерт, який спрацьовуватиме не тоді, коли користувач успішно отримає права, а коли він не зміг їх отримати, хоч і намагався. Для цього зробимо такий запит:
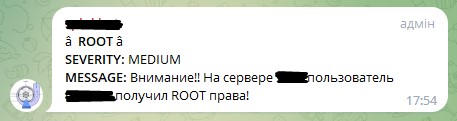
index="linux_auditd" action=failure type=USER_AUTH | table UID host addr
Цей запит дасть нам помилки під час авторизації користувача. Зробимо з нього алерт, але з тією відмінністю від попереднього, що спрацьовуватиме він не за одноразовою подією (може просто адмін не з першого разу по клавіатурі потрапив), а при виникненні 10 таких подій у період 5 хвилин. Також врахуємо, що після спрацьовування алерту він повинен тимчасово відключитися на 6 хвилин, щоб не перераховувати значення за останні 5 хвилин, які вже порахував.
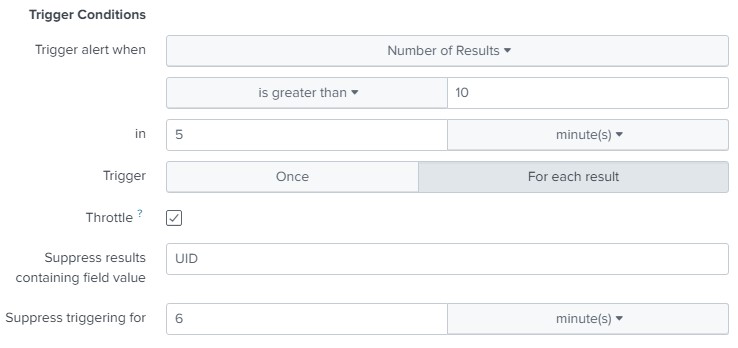
У такому разі Ви отримаєте таке повідомлення у телеграмі:
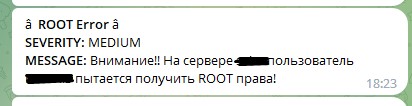
У цьому прикладі ми враховуємо кількість повторень протягом 5 хвилин значення поля UID, але можна настроїти алерт просто на кількість помилок, якщо припустити, що підбір пароля здійснюється не для одного облікового запису, а для різних обліків, хоча найчастіше підбирають пароль до користувача root або іншому, наперед відомому, користувачеві.
Також можна налаштовувати й інші реакції. Наприклад, при 1000 помилках протягом 5 хвилин виконати скрипт, який додасть або включить на фаєрфолі правило, ізолююче атакуючий хост. IP цього хоста нам поверне змінна addr із нашого запиту.
Таким чином, шановні читачі, ми з Вами розібралися, що програмне рішення Splunk – це дуже потужний інструмент для централізованого збирання, зберігання та обробки журналів OS LINUX.
Вивчили, як проводиться інсталяція, конфігурування та керування Splunk'om.
На прикладі LINUX-daemon'a auditd навчилися постачати події в індекс Splunk, і поспостерігали, як здійснюється налаштування та відправлення оповіщень Splunk'a у зовнішній канал (Telegram).
Далі буде!

